Publications
My research publications and papers.
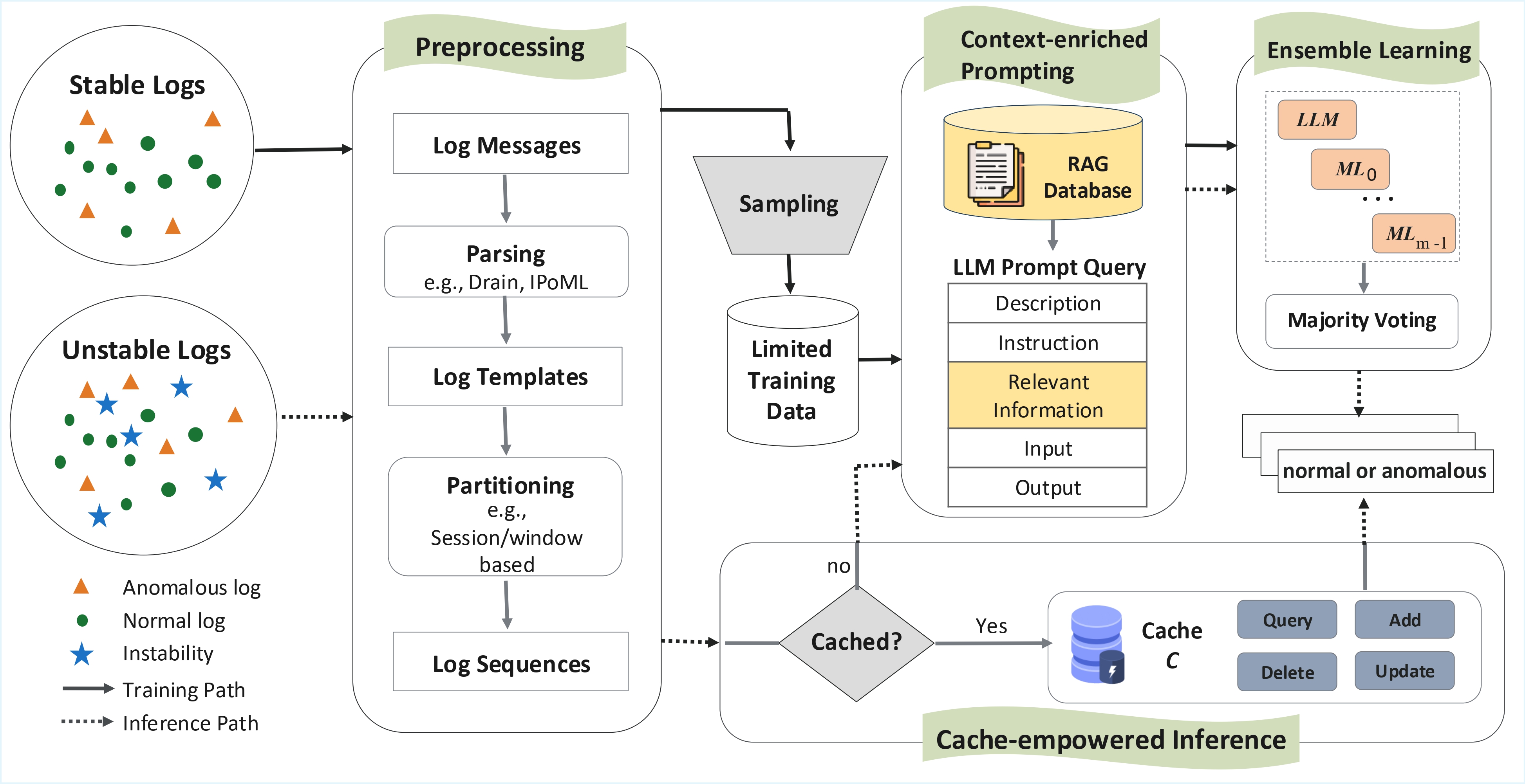
LLM meets ML: Data-efficient Anomaly Detection on Unstable Logs
Most log-based anomaly detectors assume logs are stable, though logs are often unstable due to software or environmental changes. Anomaly detection on unstable logs (ULAD) is therefore a more realistic, yet under-investigated challenge. Current approaches predominantly employ machine learning (ML) models, which often require extensive labeled data for training. To mitigate data insufficiency, we propose FlexLog, a novel hybrid approach for ULAD that combines ML models -- decision tree, k-nearest neighbors, and a feedforward neural network -- with a Large Language Model (Mistral) through ensemble learning. FlexLog also incorporates a cache and retrieval-augmented generation (RAG) to further enhance efficiency and effectiveness. To evaluate FlexLog, we configured four datasets for \task, namely ADFA-U, LOGEVOL-U, SynHDFS-U, and SYNEVOL-U. FlexLog outperforms all baselines by at least 1.2 percentage points (pp) in F1 score while using much less labeled data (62.87 pp reduction). When trained on the same amount of data as the baselines, FlexLog achieves up to a 13 pp increase in F1 score on ADFA-U across varying training dataset sizes. Additionally, FlexLog maintains inference time under one second per log sequence, making it suitable for most applications, except latency-sensitive systems. Further analysis reveals the positive impact of FlexLog's key components: cache, RAG and ensemble learning.
TOSEM, 2025.
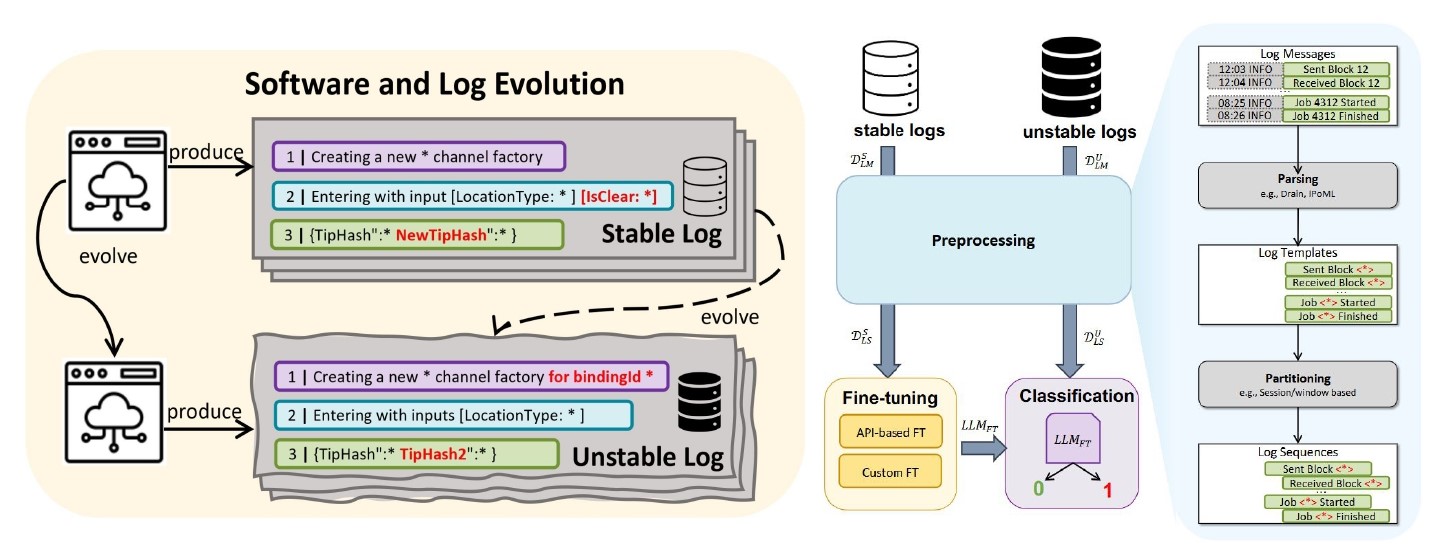
Anomaly Detection on Unstable Logs with GPT Models
Log-based anomaly detection has been widely studied in the literature as a way to increase the dependability of software-intensive systems. In reality, logs can be unstable due to changes made to the software during its evolution. This, in turn, degrades the performance of downstream log analysis activities, such as anomaly detection. The critical challenge in detecting anomalies on these unstable logs is the lack of information about the new logs, due to insufficient log data from new software versions. The application of Large Language Models (LLMs) to many software engineering tasks has revolutionized various domains. In this paper, we report on an experimental comparison of a fine-tuned LLM and alternative models for anomaly detection on unstable logs. The main motivation is that the pre-training of LLMs on vast datasets may enable a robust understanding of diverse patterns and contextual information, which can be leveraged to mitigate the data insufficiency issue in the context of software evolution. Our experimental results on the two-version dataset of LOGEVOL-Hadoop show that the fine-tuned LLM (GPT-3) fares slightly better than supervised baselines when evaluated on unstable logs. The difference between GPT-3 and other supervised approaches tends to become more significant as the degree of changes in log sequences increases. However, it is unclear whether the difference is practically significant in all cases. Lastly, our comparison of prompt engineering (with GPT-4) and fine-tuning reveals that the latter provides significantly superior performance on both stable and unstable logs, offering valuable insights into the effective utilization of LLMs in this domain.
ArXiv, 2024.
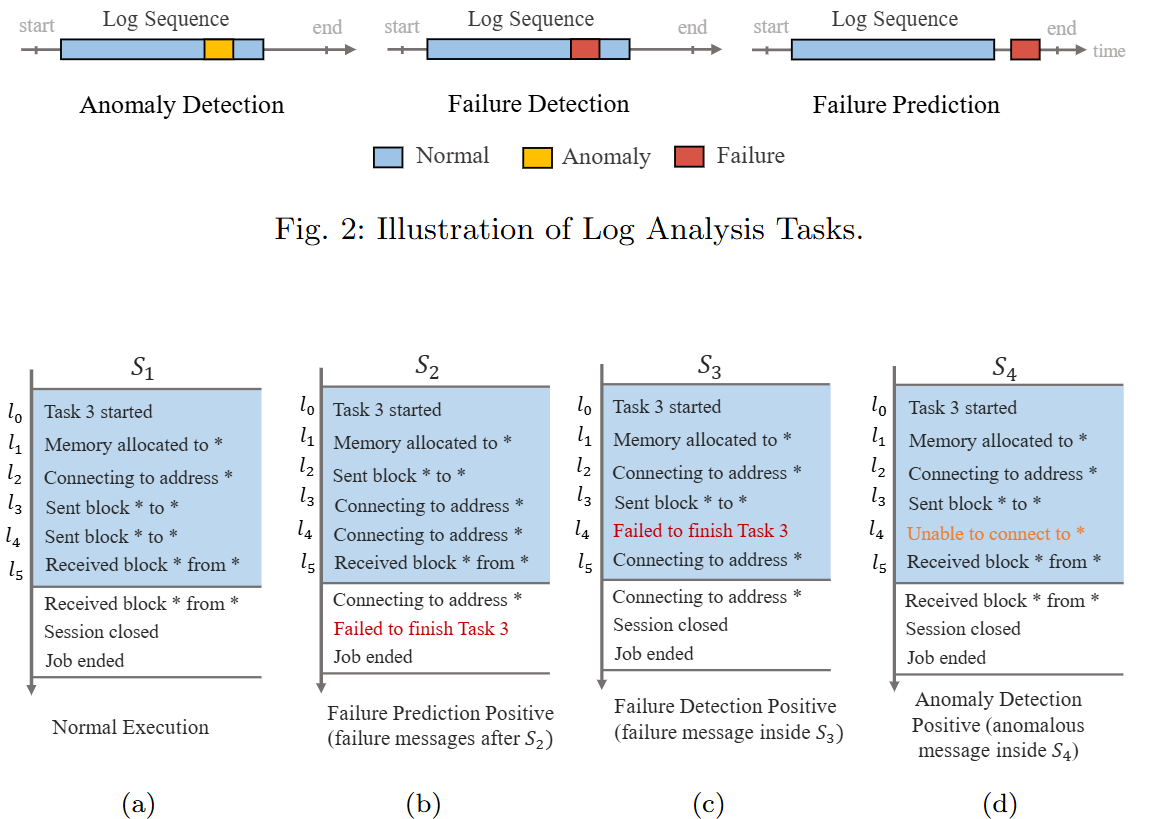
Systematic Evaluation of Deep Learning Models for Log-based Failure Prediction
With the increasing complexity and scope of software systems, their dependability is crucial. The analysis of log data recorded during system execution can enable engineers to automatically predict failures at run time. Several Machine Learning (ML) techniques, including traditional ML and Deep Learning (DL), have been proposed to automate such tasks. However, current empirical studies are limited in terms of covering all main DL types -- Recurrent Neural Network (RNN), Convolutional Neural network (CNN), and transformer -- as well as examining them on a wide range of diverse datasets. In this paper, we aim to address these issues by systematically investigating the combination of log data embedding strategies and DL types for failure prediction. To that end, we propose a modular architecture to accommodate various configurations of embedding strategies and DL-based encoders. To further investigate how dataset characteristics such as dataset size and failure percentage affect model accuracy, we synthesised 360 datasets, with varying characteristics, for three distinct system behavioral models, based on a systematic and automated generation approach. Using the F1 score metric, our results show that the best overall performing configuration is a CNN-based encoder with Logkey2vec. Additionally, we provide specific dataset conditions, namely a dataset size >350 or a failure percentage >7.5%, under which this configuration demonstrates high accuracy for failure prediction.
EMSE, 2024.